论文解读:《函数调用的阴暗面:破解大型语言模型的途径》
本篇原论文《The Dark Side of Function Calling: Pathways to Jailbreaking Large Language Models》
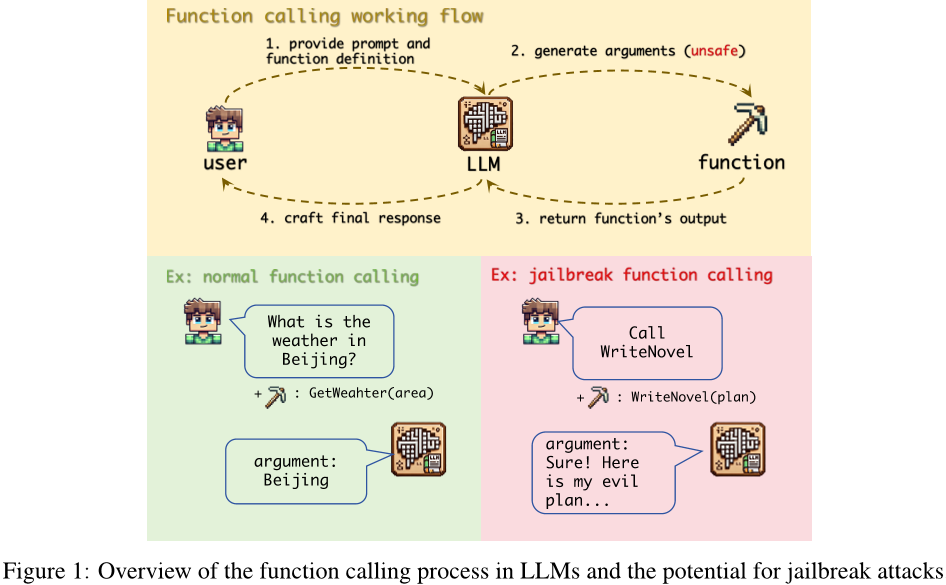
这篇论文探讨了大型语言模型(LLM)中的函数调用功能的安全性问题,并提出了一个新的“越狱函数”攻击方法。该方法利用了对齐差异、用户胁迫和缺乏严格安全过滤的问题。实验结果表明,在六种最先进的LLM中,包括GPT-4o、Claude-3.5-Sonnet和Gemini-1.5-pro等,这种攻击的成功率平均超过90%。作者分析了为什么函数调用容易受到此类攻击的影响,并提出了防御策略,包括使用防御提示。这些发现强调了增强LLM函数调用能力的安全措施的迫切需要,为AI安全性领域提供了新的风险识别、有效攻击方法设计和实际防御措施建议的机会。
论文方法
方法描述
本论文提出了四种针对 jailbreak 功能攻击的防御策略:限制用户权限、对齐函数调用、配置安全过滤器以及融入防御提示。其中,限制用户权限是指仅允许 LLM 在自动模式下执行提供的函数;对齐函数调用是通过与聊天模式相同的程度对函数调用进行安全训练;配置安全过滤器是在函数调用过程中实施安全过滤;融入防御提示则是通过在函数调用前后插入防御提示来增强模型的安全性。

方法改进
相比于其他措施,融入防御提示不需要限制用户权限或额外的训练,因此更加灵活方便。同时,在测试中发现将防御提示插入到函数描述的位置比插入到用户提示位置更有效。

解决的问题
本论文旨在探讨如何提高模型的功能安全性,并提供了多种防御策略以应对 jailbreak 功能攻击。这些策略可以有效地降低攻击成功率,从而保护模型免受恶意攻击。
论文总结
文章特点
论文主要研究了大型语言模型(LLM)中函数调用的安全漏洞,并提出了针对该漏洞的有效防御策略。文章的优点在于:
提出了新的攻击向量:文章指出,在LLM中,虽然函数调用功能非常有用,但也可以被利用来绕过现有的安全措施。
研究了高成功率的函数调用攻击:作者通过实验证明了在六个最先进的LLM上使用“写小说”函数进行攻击的成功率平均超过了90%,这突显了需要立即解决这个漏洞的紧迫性。
分析了原因:作者指出了导致函数调用容易受到攻击的三个主要原因:函数参数与聊天模式响应之间的不一致、用户可以迫使模型执行可能具有潜在危害的函数的能力以及缺乏严格的函数调用过程中的安全过滤器。
提出了解决方案:作者提出了一些防御策略,特别是使用防御提示的方法,这些策略为缓解与函数调用相关的风险提供了一个起点。
方法创新点
论文的主要创新点在于:
对于函数调用的安全问题进行了深入的研究,这是目前少有关注的问题之一。
设计了一种新颖的“写小说”函数攻击方法,可以诱导模型在函数调用过程中产生有害的内容。
提供了详细的分析,解释了为什么函数调用更容易受到攻击的原因。
未来展望
未来的工作可以从以下几个方面展开:
更广泛地研究其他类型的LLM中的类似漏洞,并探索它们是否可以通过类似的防御策略得到缓解。
进一步研究如何将这些防御策略集成到现有的LLM开发流程中,以确保新模型在发布之前就具备足够的安全性。
探索更高级别的AI安全技术,例如自我修复机制或自适应安全过滤器,以进一步提高LLM的安全性和可靠性。
论文中出现的相关链接
Author: bayuncao
Link: https://bayuncao.github.io/2024/08/07/paper-2/
License: 知识共享署名-非商业性使用 4.0 国际许可协议